An Overview of Attention Mechanisms in Neural Networks
Summary:
- Limits of “vanilla” seq2seq models
- Additive attention
- Multiplicative attention
- Self-attention
- Honorable mentions
- Sources
Attention in Deep Learning is one of the most powerful and interesting tools of the last years. It revolutionized the implementation and the application of seq2seq architectures, and consequently the whole field of NLP.
One of the most fascinating aspects of attention mechanisms is a strong biological analogy: the way it works is very similar to the way we usually picture our attention. In fact, we can think of it as some sort of “mental heatmap” in which the most important elements of our empirical input are “fired up”, to the detriment of its less relevant bits. The whole point of attention mechanisms is just that: let’s teach artificial neural networks to understand what elements of its input it should care about the most, and what others instead can be overlooked.
Limits of “vanilla” Seq2seq models
Current attention mechanisms come from research on Seq2seq networks, which goal is to transform an input sequence into another (sorry for oversimplifying, but I don’t want to waste your time). Before the rise of Transformer networks, Seq2seq models use to be the SOTA in important fields of Deep Learning such as NMT, chatbots, and text summarization.
Their problems are well known: they struggle to process long sequences.
Imagine a typical seq2seq model with Recurrent (LSTM or GRU) layers:

Thn encoder generates a representation of the input sequence, and a decoder receives it and produces another sequence as output. What happens when a very relevant bit of information is located far away in the input sequence (let’s say at the very beginning of it)? The Encoder should generate a representation of the whole input in a single vector, making it very hard for that signal to traverse intact all Recurrent cells and reach the layer output. That’s why “vanilla” Seq2seq struggle in translating long pieces of text. (The introduction of bidirectional Recurrent layers improved significantly their performance, but it alleviated the problem rather than solving it.)
Moreover, it’s not how we translate things. Imagine someone told you to translate an article from Italian to English: you don’t read the whole text, memorize it, and then say: “Got it! Let me write it all down in English!”. That’t not how we do. Rather, we’d constantly check the original and the translation, jumping from one to the other countless times.
That’s what attention mechanisms are meant to accomplish.
In this post I will review the three main kinds of attention mechanism:
- Additive attention
- Multiplicative attention
- Self-attention
I will explain how they work, and how attention layers can be quickly called or implemented in TensorFlow 2.
Additive attention
It’s the first successful formulation of attention mechanism, proposed by Bahdanau et al. in 2014. That’s what they did: in a Seq2seq model, between encoder and decoder, they added an Attention block:

Although the image above seems significantly more complicated than before, I promise it isn’t.
The attention block, at each time step , receives the encoder’s output at
and the decoder’s state at
, and produces a context vector (that’s how they call the attention’s output) that is used to compute the decoder’s state at time
.
That’s why you see the decoder sending and receiving stuff to and from the attention block.
More closely, it works like this:
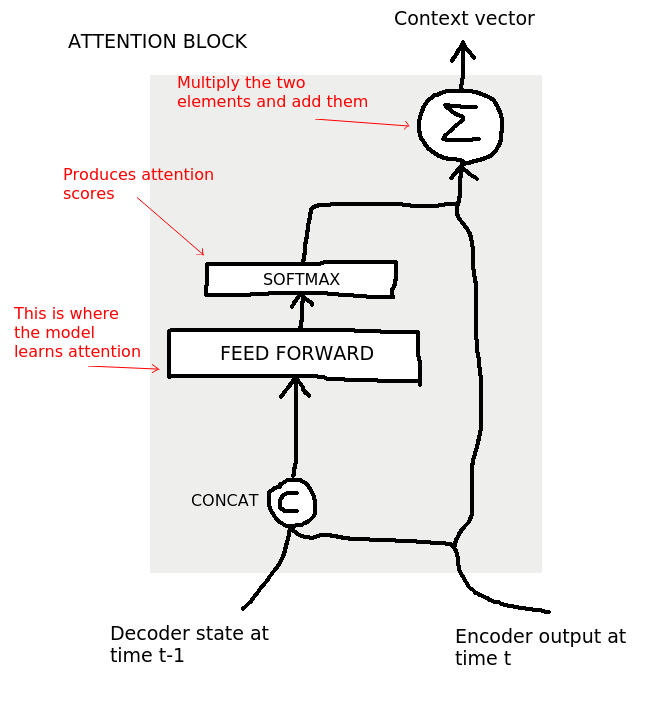
At each time step the decoder can “choose what to look at” by combining together its previous hidden state (at ) and the current Encoder output (at
).
The term “additive” comes from their combination, that is why it was also called concatenative attention.
Attention allows the decoder to look at the same time to multiple steps of encoder sequence, even far back in time. In a way, the attention mechanism plays a role not too different from the one that is played by skip connections in CNNs. It represents a “shortcut” for useful signals present in the input sequence, that now don’t have to traverse all the layer cells before affecting the output.
Since TensorFlow 2.1, Bahdanau is already available among keras.layers as AdditiveAttention().
As explained in the docs, it takes three inputs: query, value and key tensors (Q, K, V, respectively). Most of the times however, only Q and V are fed: the same tensor for V is used for K as well.
What do Q, V, K tensors mean? This nomenclature comes from retrieval systems: when you formulate a query to access some information from a larger set of data, a system will find the values that better correspond to it, based on a set of similarity keys. Attention mechanisms can be seen as some sort of information retrieval systems, in which Neural Networks learn to retrieve the most important information to pay attention to in order to produce the current output.
In Seq2seq models specifically, Q is the decoder’s state at time , and V is the encoder’s states at time
.
K and V are the same in this case, therefore there’s no need to specify K.
Multiplicative attention
This formulation of attention was proposed one year later by Luong et al. [2015].
The difference is in the way the two inputs of the attention block (decoder’s state at time step and encoder outputs at time step
) are combined together.
In this case, attention is computed as a dot product of these two elements.
Multiplicative Attention was proved superior in performance, while allowing for faster training at the same time. Because of this, this formulation of Attention is now considered the standard for Seq2seq implementations, and when we generically refer to “Attention” we mean Luong et al.’s.
In TensorFlow 2, Multiplicative Attention is implemented in keras.layers as Attention() and follows exactly the same syntax of AdditiveAttention().
Self-attention
Since its first applications, attentional models have been so successful to push a group of researchers at Google Brain [Vaswani et al. 2018] to abandon LSTM and GRU technology and invent a new kind of neural architecture based exclusively on attention.
That was the birth of the Transformer.
This architecture has an Encoder and a Decoder, each composed of an optional number of blocks that look more or less like this:
The Transformer is more complex than previous Seq2seq models (IMHO), and to describe it in detail a whole new blog post would be necessary (actually, I’m thinking of it). In the meantime, I strongly suggest you to read the excellent post The Illustrated Transformer by Jay Alammar, a must read article on this topic.
What is most interesting here is to explore the self-attention mechanism, proposed specifically for this new architecture.
Previous attention mechanisms are all relative, i.e. a decoder learns to produce an output sequence while paying attention to another sequence (produced by the encoder). Here instead, the input sequence pays attention to itself.
This formulation is also called scaled dot-product attention.
It is “dot-product”, meaning it’s of multiplicative kind, and “scaled” because of the constant scaling parameter
( is the square root of the number of units in the K vector).
Its purpose is to stabilize the softmax function:
values otherwise too large would push the softmax in extreme regions with extremely small gradients,
causing suboptimal performance (please refer to the original paper for a deeper explanation).
Another important aspect is that the Transformer doesn’t simply uses one Attention mechanism, it runs many in parallel (in the original paper, eight). That’s what the authors called multi-head attention. The logic behind implementing multiple, identical self-attention mechanisms in parallel is that in this way the network can use different mechanisms to pay attention at different things at the same time.
Even though self-attention seems strictly connected with Trasformer networks (and it is), it could in theory be applied to other architectures as well. For example, it has been used in GANs and Reinforcement Learning].
TensorFlow 2 does not contain a built-in self-attention layer (yet?), but it is possible to implement it, and there is more than one way to do it.
For example, if you just want to implement a bare self-attention mechanism (i.e. an attention layer in which “the input pays attention to itself”)
then you can simply use an Attention() layer and feed the same input tensor X twice:
from tensorflow.keras.layers import Attention
self_attention = Attention(use_scale=True)([X, X])
This will return a simple self-Attention tensor that you can use in a neural network of your choice, not necessarily a Transformer.
Notice the argument use_scale=True: it works similarly to the scaling factor used in scaled dot-product attention, but it’s not the same:
in Transformer networks this scaling factor is constant, while in this case it is learned.
But let’s assume you want to implement the exactly the same attention mechanism used in Transformers: on the TensorFlow website a whole implementation is available. First, we have this function for scaled dot-product attention:
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
Second, a new Self-Attention layer can be then implemented:
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
This will work just like any other Keras layer.
Honorable mentions
Attention is one of the most exciting developments in the fiels of Deep Learning, and the rise of Transformers is a proof of their absolute importance. There are many formulations of Attention that I overlooked because of a lack of space. One notable mention is the difference between Local and Global Attention, where one is confined to a given time window in the input sequence, while the other uses all encoder’s states.
Countless formulations of attention mechanism have been invented since 2014. For example Yang et al. [2019] proposed convolutional self-attention, while Yin et al. [2019] developed attention-based CNNs. Lots of work has been done to extend applications of attention from NLP to computer vision. The Image Transformer is one of the most notable examples [Parmar et al. 2018].
Sources
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Géron, A. (2019). Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems. O’Reilly Media; particularly Chapter 16, Natural Language Processing with RNNs and Attention.
- Luong, M. T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
- Shen, X., Yin, C., & Hou, X. (2019, April). Self-Attention for Deep Reinforcement Learning. In Proceedings of the 2019 4th International Conference on Mathematics and Artificial Intelligence (pp. 71-75).
- The Illustrated Transformer by Jay Alammar.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- Yang, B., Wang, L., Wong, D., Chao, L. S., & Tu, Z. (2019). Convolutional self-attention networks. arXiv preprint arXiv:1904.03107.
- Yin, W., Schütze, H., Xiang, B., & Zhou, B. (2016). Abcnn: Attention-based convolutional neural network for modeling sentence pairs. Transactions of the Association for Computational Linguistics, 4, 259-272.
- Zhang, H., Goodfellow, I., Metaxas, D., & Odena, A. (2019, May). Self-attention generative adversarial networks. In International Conference on Machine Learning (pp. 7354-7363). PMLR.
Other usefuls resources:
- Attention in RNNs is a very nice article, it was of great help when I was a complete beginner and wanted to understand the very basics of Attention. It’s all about the Bahdanau mechanism, but its insights can be easily extended to Luong’s.
- The full 2019 Stanford course CS224N: Natural Language Processing with Deep Learning, by Chris Manning. If you want to go for the heavy stuff, this is highly technical but extremely rewarding. The quality of guest lecturers is extremely high.
- The official TensorFlow tutorial on how to implement a Transformer model for language understanding.
- A lecture on Attention is all you need by Research Scientist at Google Brain Łukasz Kaiser.